
Deep Dive: Understanding Ripple's Runtime and Reactivity System (For Nerds)
Introduction
Ripple is a compile-time reactive framework that achieves fine-grained reactivity through a sophisticated runtime system. Unlike virtual DOM frameworks that diff entire component trees, Ripple tracks dependencies at the granular level of individual expressions and only re-executes the minimal set of blocks necessary when tracked values change.
To understand this system, we need to trace how reactive code flows from source to execution. The journey begins with compilation, where Ripple syntax is transformed into JavaScript with runtime calls. Then, during execution, the runtime system tracks dependencies, detects changes, and propagates updates through a tree of blocks.
In this post, we'll dissect Ripple's reactivity system by tracing a complete example component through its entire lifecycle. We'll examine how the compiler transforms reactive syntax into runtime calls, how dependencies are tracked during execution, how updates propagate through the block tree, and the data structures that make it all work.
Prerequisites:
- Familiarity with JavaScript
- Basic understanding of reactive programming
- Comfort reading implementation details
What you'll learn:
- How
@countbecomes a dependency registration - How
track()creates reactive values - How the block tree executes updates
- How derived values compute lazily
Our Example Component
To understand how Ripple's reactivity system works, we'll trace a complete example component through its entire lifecycle. This component demonstrates the key reactivity features we need to understand.
import { track } from 'ripple';
export component Counter() {
// Simple tracked value - stores a number
let count = track(0);
// Derived value - computed from count
let double = track(() => @count * 2);
// Boolean flag for conditional rendering
let showDouble = track(true);
<div>
{/* Display count - this will update when count changes */}
<p>{"Count: "}{@count}</p>
{/* Conditional block - shows/hides based on showDouble */}
if (@showDouble) {
<p>{"Double: "}{@double}</p>
}
{/* Buttons that mutate tracked values */}
<button onClick={() => @count++}>{"Increment"}</button>
<button onClick={() => @showDouble = !@showDouble}>{"Toggle"}</button>
</div>
}
This component contains three tracked values: count (a simple number), double (computed from count), and showDouble (a boolean flag). It also demonstrates conditional rendering and event handlers that mutate tracked values.
The key question we'll answer: When count changes from 0 to 1, what exactly happens? How does the system know which blocks to re-execute? How does double automatically recompute? Let's trace through each phase of the component's lifecycle.
Phase 1: Compilation - From Ripple to JavaScript
Before our component can run, Ripple's compiler transforms it into optimized JavaScript. The compilation process happens in three phases: parsing, analysis, and transformation. Understanding this transformation is crucial because it shows how reactive syntax becomes runtime calls that enable dependency tracking.
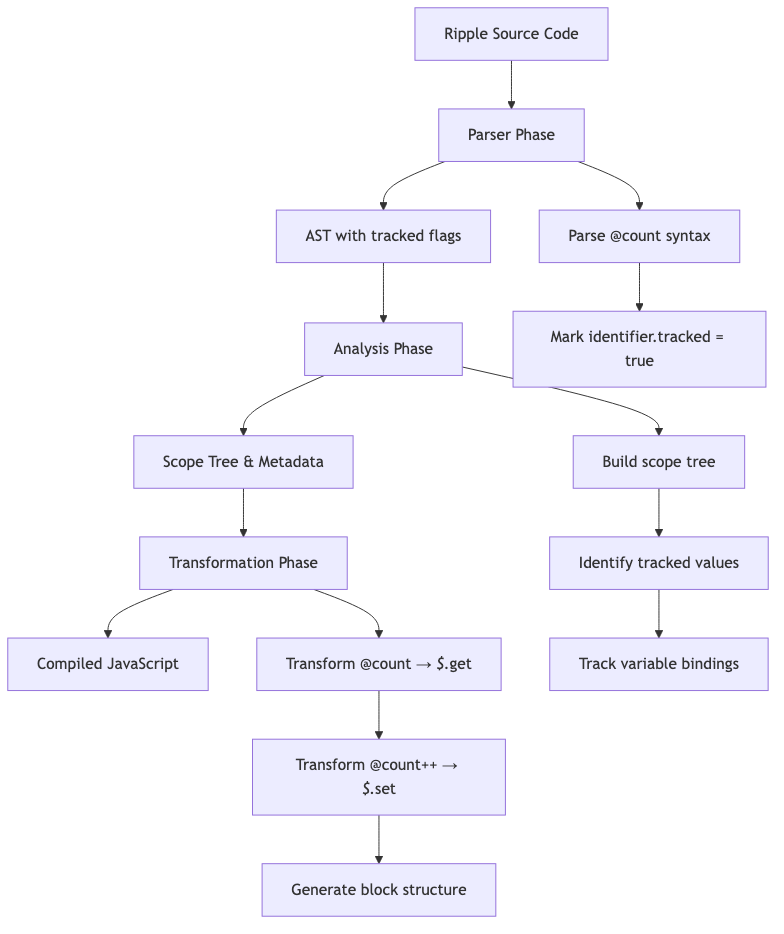
Step 1.1: Parser Transformation
The parser reads our Ripple syntax and builds an Abstract Syntax Tree (AST). The key transformation is how @count is handled.
Original Ripple code:
let count = track(0);
let double = track(() => @count * 2);
What the parser sees:
@countis a special token (not a regular identifier)- The parser strips the
@and marks the identifier astracked: true
AST Structure:
// First variable declaration
VariableDeclaration {
declarations: [{
id: Identifier { name: "count" },
init: CallExpression {
callee: Identifier { name: "track" },
arguments: [Literal { value: 0 }]
}
}]
}
// Second variable declaration (note the tracked flag!)
VariableDeclaration {
declarations: [{
id: Identifier { name: "double" },
init: CallExpression {
callee: Identifier { name: "track" },
arguments: [ArrowFunctionExpression {
body: BinaryExpression {
operator: "*",
left: Identifier {
name: "count",
tracked: true // ← This flag is crucial!
},
right: Literal { value: 2 }
}
}]
}
}]
}
The tracked: true flag is crucial - it tells the transformer that this identifier needs runtime dependency tracking. Without this flag, the transformer wouldn't know to generate the special _$_.get() call that registers dependencies.
Step 1.2: Analysis Phase
The analyzer walks the AST and builds a scope tree - a map of all variables and where they're used. This helps the transformer generate correct code.
Scope Analysis:
ComponentScope {
declarations: {
"count": Binding {
node: Identifier,
initial: CallExpression { callee: "track" },
kind: "let",
metadata: {
is_tracked: true // ← This is a tracked value
}
},
"double": Binding {
node: Identifier,
initial: CallExpression {
callee: "track",
arguments: [Function] // ← Function means it's derived
},
kind: "let",
metadata: {
is_tracked: true,
is_derived: true // ← Computed from other values
}
},
"showDouble": Binding {
node: Identifier,
initial: CallExpression { callee: "track" },
kind: "let",
metadata: { is_tracked: true }
}
}
}
What this tells us:
countis a simple tracked value (stores a number)doubleis a derived value (computed fromcount)showDoubleis a simple tracked value (stores a boolean)
The analyzer also tracks where each variable is referenced, which helps with optimization.
Step 1.3: Transformation Phase
The transformer generates optimized JavaScript code. This is where the magic happens - reactive syntax becomes runtime calls.
Transformed Component (simplified):
import * as _$_ from 'ripple/internal/client';
import { track } from 'ripple';
function Counter(props) {
// Create component context (tracks component state)
const component_ctx = _$_.create_component_ctx();
_$_.push_component();
// Tracked value creation
// Note: component_ctx is passed as 4th argument
let count = track(0, undefined, undefined, component_ctx);
let double = track(() => _$_.get(count) * 2, undefined, undefined, component_ctx);
let showDouble = track(true, undefined, undefined, component_ctx);
// Root block - wraps entire component rendering
return _$_.root(() => {
// Template creation (HTML string → DOM)
const __anchor = document.createTextNode('');
const __template0 = _$_.template('<div><p><!></p><!></div>');
const __fragment = __template0();
__anchor.before(__fragment);
// Count text rendering block
const __text0 = __fragment.querySelector('p');
_$_.render(() => {
// @count becomes _$_.get(count)
_$_.set_text(__text0.firstChild, 'Count: ' + _$_.get(count));
});
// Conditional block for showDouble
const __anchor1 = __fragment.querySelector('p').nextSibling;
_$_.if(__anchor1, (set_branch) => {
// @showDouble becomes _$_.get(showDouble)
if (_$_.get(showDouble)) {
set_branch((anchor) => {
const __template1 = _$_.template('<p><!></p>');
const __fragment1 = __template1();
anchor.before(__fragment1);
_$_.render(() => {
// @double becomes _$_.get(double)
_$_.set_text(__fragment1.firstChild, 'Double: ' + _$_.get(double));
});
});
}
});
_$_.pop_component();
return () => { /* teardown function */ };
}, component_ctx);
}
Key Transformations:
| Ripple Syntax | Compiled JavaScript | What It Does |
|---|---|---|
@count | _$_.get(count) | Read tracked value, register dependency |
@count++ | _$_.set(count, _$_.get(count) + 1) | Update tracked value, schedule update |
track(() => @count * 2) | track(() => _$_.get(count) * 2) | Create derived value |
if (@showDouble) | _$_.if(anchor, (set_branch) => { if (_$_.get(showDouble)) ... }) | Conditional rendering block |
Notice how @count becomes _$_.get(count). This function call is where dependency tracking happens. When the compiled code executes, _$_.get(count) will read the value and register count as a dependency of the currently executing block.
Now that we understand how the code is transformed, let's see what happens when this compiled code actually runs.
Visual Overview: The Reactivity Flow
Before we dive deep, here's a high-level view of how reactivity works:

Key Variables to Watch:
| Variable | Purpose | Changes When |
|---|---|---|
count.__v | Current value | set() called |
count.c | Clock value | set() called (increments) |
block.d | Dependency chain | get() called (if tracking) |
dependency.c | Stored clock | register_dependency() called |
tracking | Enable/disable tracking | Block execution context |
Phase 2: Initial Execution - Component Mount
Now that we've seen how the code is compiled, let's trace what happens when the component actually executes. This is where the runtime system comes alive, creating tracked values, building the block tree, and registering dependencies.
Step 2.1: Component Function Call
When we mount the component:
mount(Counter, { target: document.getElementById('root') });
Global Runtime State (Initial):
// These global variables track the current execution context
active_component = null // No component active yet
active_block = null // No block executing
active_reaction = null // No reactive computation running
tracking = false // Dependency tracking disabled
clock = 0 // Global clock for change detection
queued_root_blocks = [] // Empty update queue
old_values = new Map() // Empty map for teardown values
These global variables form the execution context. As blocks execute, these variables change to track what's currently happening. When a block reads a tracked value with _$_.get(), it uses active_reaction to know where to register the dependency.
Step 2.2: Tracked Value Creation
When we execute let count = track(0, ...), we're creating a reactive value. Let's see exactly what happens.
Code:
let count = track(0, undefined, undefined, component_ctx);
Algorithm: track(value, get, set, block)
FUNCTION track(0, undefined, undefined, component_ctx):
// Step 1: Check if already tracked (idempotent)
IF is_tracked_object(0): // false - 0 is a primitive
RETURN value
// Step 2: Validate block exists
IF component_ctx IS NULL: // false
THROW TypeError('track() requires a valid component context')
// Step 3: Check if value is a function (derived value)
IF typeof 0 === 'function': // false
RETURN derived(...)
// Step 4: Create simple tracked value
RETURN tracked(0, component_ctx, undefined, undefined)
END FUNCTION
Algorithm: tracked(value, block, get, set)
FUNCTION tracked(0, component_ctx, undefined, undefined):
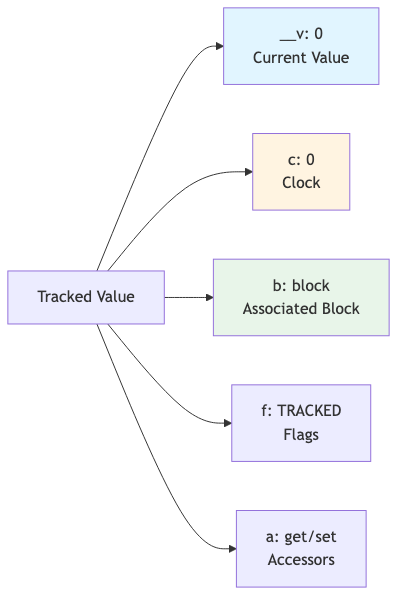
RETURN {
__v: 0, // Current value
a: { // Accessors (get/set functions)
get: undefined,
set: undefined
},
b: component_ctx, // Associated block (for scheduling updates)
c: 0, // Clock value (incremented on change)
f: TRACKED // Flags (TRACKED = simple value, not derived)
}
END FUNCTION
Result - count object:
count = {
__v: 0, // The actual value
a: { get: undefined, set: undefined },
b: component_ctx, // Which block to update when this changes
c: 0, // Clock value (starts at 0)
f: TRACKED // Flag: this is a simple tracked value
}
Result - showDouble object:
showDouble = {
__v: true, // The actual value
a: { get: undefined, set: undefined },
b: component_ctx, // Same block association
c: 0, // Clock value
f: TRACKED // Simple tracked value
}
Key Points:
__vstores the actual value (0 or true)b(block) is crucial - when this value changes, we'll schedule an update to this blockc(clock) starts at 0 and increments every time the value changesf(flags) tells us this is a simple tracked value, not a computed one
Tracked Value Structure:
Now let's see how the derived value double is created, which has a different structure because it's computed rather than stored directly.
Step 2.3: Derived Value Creation
Now for the interesting one - double is a derived value. It's computed from count, not stored directly.
Code:
let double = track(() => _$_.get(count) * 2, undefined, undefined, component_ctx);
Notice: We pass a function, not a value. This tells Ripple "compute this value when needed."
Algorithm: track(fn, get, set, block)
FUNCTION track(fn, undefined, undefined, component_ctx):
// fn = () => _$_.get(count) * 2
// Check if it's a function (derived value)
IF typeof fn === 'function': // true
RETURN derived(fn, component_ctx, undefined, undefined)
// Otherwise create simple tracked value
RETURN tracked(fn, component_ctx, undefined, undefined)
END FUNCTION
Algorithm: derived(fn, block, get, set)
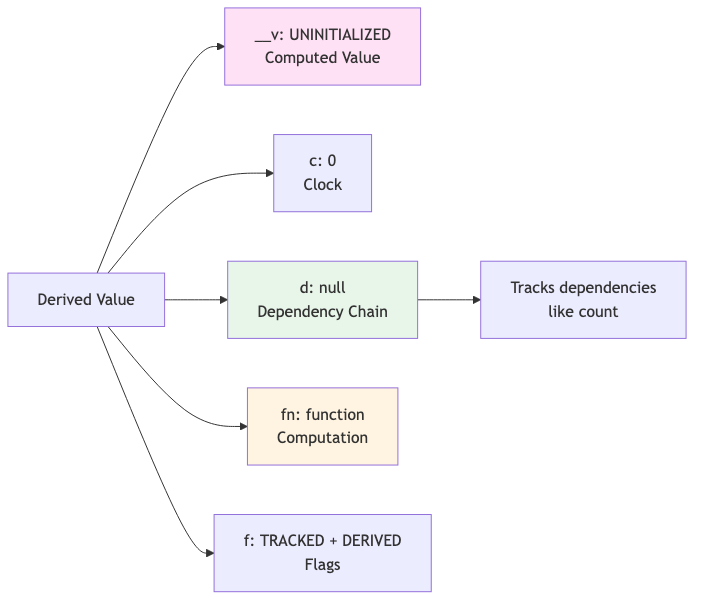
FUNCTION derived(fn, component_ctx, undefined, undefined):
RETURN {
__v: UNINITIALIZED, // Not computed yet! (lazy)
a: { get: undefined, set: undefined },
b: component_ctx, // Associated block
blocks: null, // Child blocks (created during computation)
c: 0, // Clock value
co: active_component, // Component context
d: null, // Dependency chain (empty - will be populated)
f: TRACKED | DERIVED, // Flags: both TRACKED and DERIVED
fn: fn // Computation function
}
END FUNCTION
Result - double object:
double = {
__v: UNINITIALIZED, // Not computed yet! (lazy evaluation)
a: { get: undefined, set: undefined },
b: component_ctx,
blocks: null, // Will hold child blocks created during computation
c: 0, // Clock value
co: null, // Component context
d: null, // No dependencies yet (will track count)
f: TRACKED | DERIVED, // Both flags set
fn: () => _$_.get(count) * 2 // The computation function
}
Key Differences from Simple Tracked Values:
| Property | Simple (count) | Derived (double) |
|---|---|---|
__v | Has value immediately (0) | UNINITIALIZED (lazy) |
f | TRACKED | TRACKED | DERIVED |
fn | undefined | Computation function |
d | null (not used) | null (will track dependencies) |
Derived values aren't computed until someone reads them. This lazy evaluation avoids unnecessary computation. When we first access @double, that's when double.fn() runs and double.d gets populated with dependencies.
Derived Value Structure:
With our tracked values created, the next step is to create the root block that will contain all the rendering logic.
Step 2.4: Root Block Creation
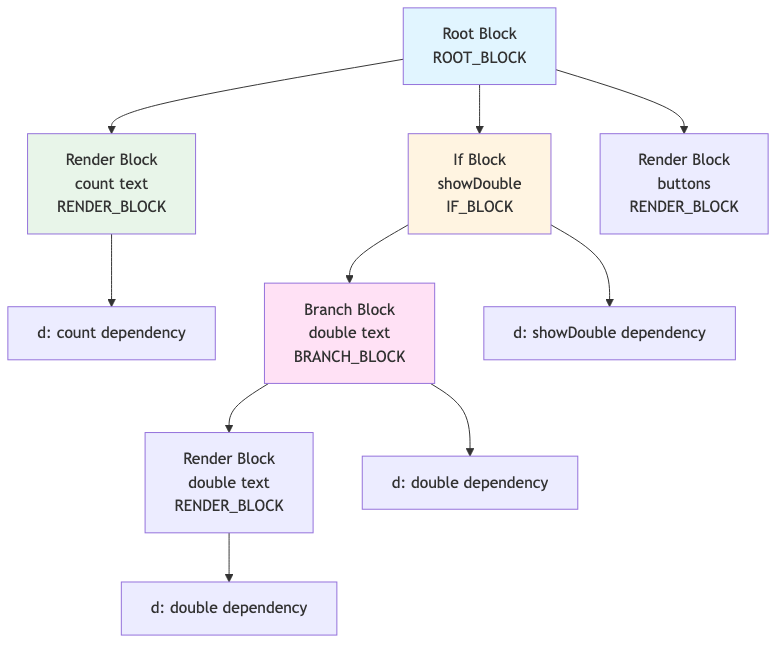
Blocks are the fundamental unit of reactive execution in Ripple. Think of them as "reactive functions" - they execute, track dependencies, and re-execute when those dependencies change.
Code:
return _$_.root(() => { /* render function */ }, component_ctx);
Algorithm: root(fn, compat, component_ctx)
FUNCTION root(fn, undefined, component_ctx):
// Create a root block (top-level block for component)
RETURN block(ROOT_BLOCK, fn, { compat: undefined }, component_ctx)
END FUNCTION
Algorithm: block(flags, fn, state, co)
FUNCTION block(ROOT_BLOCK, fn, { compat }, component_ctx):
block = {
co: component_ctx, // Component context
d: null, // Dependency chain (empty initially)
first: null, // First child block
f: ROOT_BLOCK, // Flags (ROOT_BLOCK = top-level)
fn: fn, // Function to execute
last: null, // Last child block
next: null, // Next sibling block
p: null, // Parent block (null for root)
s: { compat }, // State (DOM nodes, etc.)
t: null // Teardown function
}
// Link to parent if one exists (none for root)
IF active_block IS NOT NULL:
push_block(block, active_block)
RETURN block
END FUNCTION
Result - root_block structure:
root_block = {
co: component_ctx, // Which component owns this block
d: null, // Dependency chain (will be populated)
first: null, // Will point to first child block
f: ROOT_BLOCK, // Flag: this is a root block
fn: () => { /* render function */ }, // What to execute
last: null, // Will point to last child block
next: null, // No siblings
p: null, // No parent (it's the root!)
s: { compat: undefined }, // State storage
t: null // Teardown function (set later)
}
Block Structure Explained:
| Property | Purpose | Example |
|---|---|---|
co | Component context | Links block to component |
d | Dependency chain | Tracks which values this block depends on |
first/last | Child blocks | Forms a tree structure |
f | Flags | ROOT_BLOCK, RENDER_BLOCK, BRANCH_BLOCK, etc. |
fn | Execution function | What code to run |
p | Parent block | Links to parent in tree |
s | State | Stores DOM nodes, data, etc. |
t | Teardown | Cleanup function |
Blocks form a tree structure where the root block contains everything, and child blocks handle specific parts like rendering text or conditionals.
Block Tree Structure:
Now that the root block is created, it needs to execute to render the component.
Step 2.5: Root Block Execution
Now the root block executes. This is where the component actually renders!
Code:
run_block(root_block);
Context Before Execution:
active_block = null
active_reaction = null
tracking = false
active_dependency = null
active_component = null
Algorithm: run_block(root_block)
FUNCTION run_block(root_block):
// Step 1: Save current context (for nested execution)
previous_block = active_block // null
previous_reaction = active_reaction // null
previous_tracking = tracking // false
previous_dependency = active_dependency // null
previous_component = active_component // null
TRY:
// Step 2: Set active context
active_block = root_block // Now this block is active
active_reaction = root_block // This is the current reaction
active_component = root_block.co // Set component context
// Step 3: Cleanup (none needed on first run)
destroy_non_branch_children(root_block) // No children yet
run_teardown(root_block) // No teardown yet
// Step 4: Enable tracking? NO - ROOT_BLOCK doesn't track!
tracking = (root_block.f & (ROOT_BLOCK | BRANCH_BLOCK)) === 0
// Since root_block.f has ROOT_BLOCK flag:
// tracking = false // Important: root blocks don't track dependencies
active_dependency = null
// Step 5: Execute the render function!
result = root_block.fn(root_block.s)
// This creates child blocks, renders DOM, etc.
// Step 6: Store teardown function if returned
IF typeof result === 'function':
root_block.t = result // Save for cleanup later
// Mark parent blocks as containing teardown (none for root)
current = root_block
WHILE current IS NOT NULL AND (current.f & CONTAINS_TEARDOWN) === 0:
current.f = current.f | CONTAINS_TEARDOWN
current = current.p
// Step 7: Store dependency chain
root_block.d = active_dependency // null (tracking was false)
FINALLY:
// Step 8: Restore previous context
active_block = previous_block
active_reaction = previous_reaction
tracking = previous_tracking
active_dependency = previous_dependency
active_component = previous_component
END FUNCTION
Context After Execution:
active_block = null // Restored
active_reaction = null // Restored
tracking = false // Restored
active_dependency = null // Restored
active_component = null // Restored
Key Points:
Context Save/Restore: This allows nested block execution. When a child block runs, it can save/restore context safely.
Root Blocks Don't Track:
tracking = falsemeans root blocks don't register dependencies. They always execute when scheduled.Dependency Chain:
root_block.d = nullbecause tracking was disabled. Child blocks will have dependency chains.
Root blocks are the entry point - they always execute when their component updates. Child blocks are the ones that need fine-grained tracking. Now let's see what happens inside the render function as it creates child blocks.
Step 2.6: Template Creation
Inside the render function:
const __template0 = _$_.template('<div><p><!></p><!></div>');
const __fragment = __template0();
Algorithm: template(content, flags)
FUNCTION template('<div><p><!></p><!></div>', flags):
node = undefined // Cached template
RETURN () => {
IF node === undefined:
// Create template element
elem = document.createElement('template')
elem.innerHTML = '<div><p><!></p><!></div>'
node = elem.content // Cache it
// Clone template
clone = node.cloneNode(true)
// Assign start/end nodes
assign_nodes(first_child(clone), clone.lastChild)
RETURN clone
}
END FUNCTION
Result: DOM fragment with placeholder comment nodes (<!>) for dynamic content.
Step 2.7: Count Text Rendering - Dependency Registration
This is where dependency tracking actually happens. When we render the count text, we read @count, which triggers the dependency registration system. This is the critical moment where blocks learn which tracked values they depend on.
Code:
_$_.render(() => {
_$_.set_text(__text0.firstChild, 'Count: ' + _$_.get(count));
});
What render() does:
FUNCTION render(fn, null, 0):
// Creates a RENDER_BLOCK (not ROOT_BLOCK!)
RETURN block(RENDER_BLOCK, fn, null)
END FUNCTION
Created Block:
count_render_block = {
co: component_ctx,
d: null, // Will be populated during execution!
first: null,
f: RENDER_BLOCK, // ← Different flag from ROOT_BLOCK
fn: () => {
_$_.set_text(__text0.firstChild, 'Count: ' + _$_.get(count));
},
last: null,
next: null,
p: root_block, // ← Parent is root block
s: null,
t: null
}
Context Before Execution:
active_block = root_block
active_reaction = root_block
tracking = false // Root block doesn't track
active_dependency = null
Execution: run_block(count_render_block)
FUNCTION run_block(count_render_block):
// Save context
previous_block = active_block // root_block
previous_reaction = active_reaction // root_block
previous_tracking = tracking // false
previous_dependency = active_dependency // null
TRY:
// Set new context
active_block = count_render_block // Now this block is active
active_reaction = count_render_block // This is the reaction
active_component = component_ctx
// Enable tracking! (RENDER_BLOCK is not ROOT_BLOCK)
tracking = (count_render_block.f & (ROOT_BLOCK | BRANCH_BLOCK)) === 0
// RENDER_BLOCK doesn't have ROOT_BLOCK or BRANCH_BLOCK flags
// tracking = true // Now dependencies will be tracked!
active_dependency = null // Will be built during execution
// Execute the function - this is where dependency registration happens
result = count_render_block.fn()
// Inside: _$_.get(count) is called
// Store the dependency chain
count_render_block.d = active_dependency // Now has count dependency!
FINALLY:
// Restore context
active_block = previous_block
active_reaction = previous_reaction
tracking = previous_tracking
active_dependency = previous_dependency
END FUNCTION
Context During Execution:
active_block = count_render_block // Changed!
active_reaction = count_render_block // Changed!
tracking = true // Enabled!
active_dependency = null // Will be built
Inside count_render_block.fn(): _$_.get(count) is called
This is the critical moment! Let's trace it step by step:
Step 1: get(count)
FUNCTION get(count):
// Check if it's a tracked object
IF NOT is_tracked_object(count): // false - count IS tracked
RETURN count
// Check if it's derived
IF (count.f & DERIVED) !== 0: // false - count.f = TRACKED, not DERIVED
RETURN get_derived(count)
// It's a simple tracked value
RETURN get_tracked(count) // ← Go here!
END FUNCTION
Step 2: get_tracked(count)
FUNCTION get_tracked(count):
// Step 1: Get the value
value = count.__v // 0
// Step 2: Register dependency (THIS IS THE KEY!)
IF tracking: // true (enabled by RENDER_BLOCK)
register_dependency(count) // ← This creates the link!
// Step 3: Handle teardown (not applicable here)
IF teardown AND old_values.has(count): // false
value = old_values.get(count)
// Step 4: Apply custom getter (none)
IF count.a.get IS NOT undefined: // false
value = trigger_track_get(count.a.get, value)
RETURN value // 0
END FUNCTION
Step 3: register_dependency(count) - The Dependency Link! 🔗
This is where count_render_block learns it depends on count:
FUNCTION register_dependency(count):
// active_reaction = count_render_block (set by run_block)
// active_dependency = null (initial state)
dependency = active_dependency // null
// Create first dependency
IF dependency IS NULL: // true
dependency = create_dependency(count)
active_dependency = dependency // ← Store in global
RETURN
END FUNCTION
Step 4: create_dependency(count) - Create the Link Node
FUNCTION create_dependency(count):
reaction = active_reaction // count_render_block
existing = reaction.d // null (no dependencies yet)
// Try to recycle (none available)
IF existing IS NOT NULL: // false
// Recycle logic...
RETURN existing
// Create new dependency node
RETURN {
c: count.c, // 0 ← Clock value when registered
t: count, // ← Reference to tracked value
n: null // ← Next dependency (none yet)
}
END FUNCTION
Result - Dependency Chain Created:
// Global state updated
active_dependency = {
c: 0, // count's clock value (0)
t: count, // Reference to count object
n: null // No next dependency
}
// Block's dependency chain stored
count_render_block.d = {
c: 0,
t: count,
n: null
}
Context After Execution:
active_block = root_block // Restored
active_reaction = root_block // Restored
tracking = false // Restored
active_dependency = null // Restored
Final State:
// The block now knows it depends on count!
count_render_block = {
// ...
d: { // Dependency chain!
c: 0, // Clock value when registered
t: count, // Which value it depends on
n: null // No other dependencies
}
}
// DOM updated
// Text node now shows: "Count: 0"
What Just Happened:
- Block executed with
tracking = true _$_.get(count)called → reads value0- Dependency registered →
count_render_block.dnow points tocount - Clock value stored →
c: 0(we'll compare this later to detect changes)
The dependency chain count_render_block.d is a linked list that says: "This block depends on count, and it was registered when count's clock was 0."
Dependency Chain Structure:
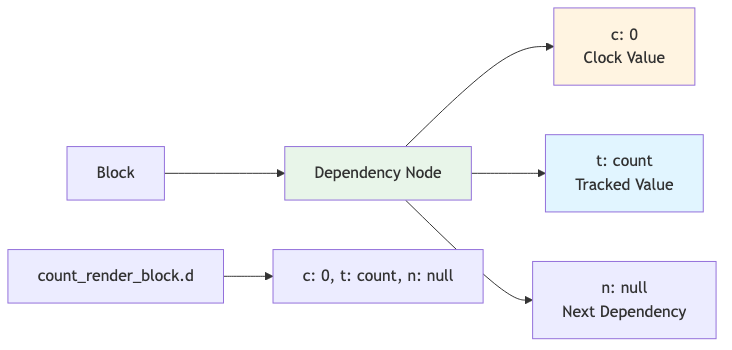
Later, when count changes, its clock increments. We can check count.c > dependency.c to see if it changed. This clock comparison is the core of Ripple's efficient change detection.
Now let's see how the conditional block for showDouble works, which will also register dependencies.
Step 2.8: Double Conditional Block
_$_.if(__anchor1, (set_branch) => {
if (_$_.get(showDouble)) {
set_branch((anchor) => { /* render double */ });
}
});
Algorithm: if_block(node, fn)
FUNCTION if_block(__anchor1, fn):
anchor = __anchor1
has_branch = false
condition = UNINITIALIZED
b = null // Branch block
set_branch = (fn, flag = true) => {
has_branch = true
update_branch(flag, fn)
}
update_branch = (new_condition, fn) => {
IF condition === new_condition: // Skip if unchanged
RETURN
// Destroy old branch
IF b !== null:
destroy_block(b)
b = null
// Create new branch if condition is truthy
IF fn !== null:
b = branch(() => fn(anchor))
}
// Render block that evaluates condition
render(() => {
has_branch = false
fn(set_branch) // Calls our function with set_branch
IF NOT has_branch:
update_branch(null, null)
}, null, IF_BLOCK)
END FUNCTION
Execution:
render()creates an IF_BLOCK- Block executes:
fn(set_branch)is called - Inside:
if (_$_.get(showDouble))evaluates
_$_.get(showDouble):
FUNCTION get(showDouble):
RETURN get_tracked(showDouble)
END FUNCTION
FUNCTION get_tracked(showDouble):
value = showDouble.__v // true
// Register dependency
IF tracking: // true
register_dependency(showDouble)
RETURN value // true
END FUNCTION
Dependency registered:
if_block.d = {
c: 0,
t: showDouble,
n: null
}
Since the condition is true, set_branch() is called, which creates a branch block. This branch block will render the double value. Inside the branch block, when we access @double, this triggers the first computation of the derived value.
Branch block execution:
branch_block = {
co: component_ctx,
d: null,
f: BRANCH_BLOCK,
fn: (anchor) => {
const __template1 = _$_.template('<p><!></p>');
const __fragment1 = __template1();
anchor.before(__fragment1);
_$_.render(() => {
_$_.set_text(__fragment1.firstChild, 'Double: ' + _$_.get(double));
});
},
p: if_block,
// ...
}
Inside branch: _$_.get(double)
This is the first access to the derived value, which means it needs to be computed for the first time.
Algorithm: get(double)
FUNCTION get(double):
// double is derived
IF (double.f & DERIVED) !== 0: // true
RETURN get_derived(double)
END FUNCTION
Algorithm: get_derived(double)
FUNCTION get_derived(double):
// Update derived value
update_derived(double)
// Register dependency
IF tracking: // true
register_dependency(double)
// No custom getter
IF double.a.get IS NOT undefined: // false
double.__v = trigger_track_get(double.a.get, double.__v)
RETURN double.__v
END FUNCTION
Algorithm: update_derived(double)
FUNCTION update_derived(double):
value = double.__v // UNINITIALIZED
// Recompute (uninitialized)
IF value === UNINITIALIZED OR is_tracking_dirty(double.d): // true
value = run_derived(double)
// Update if changed
IF value !== double.__v: // true
double.__v = value // 0
double.c = increment_clock() // 1
END FUNCTION
Algorithm: run_derived(double)
FUNCTION run_derived(double):
// Save context
previous_block = active_block // branch_block
previous_reaction = active_reaction // branch_block
previous_tracking = tracking // true
previous_dependency = active_dependency // null
previous_component = active_component // component_ctx
previous_is_mutating_allowed = is_mutating_allowed // true
TRY:
// Set context for computation
active_block = null
active_reaction = double // Derived value is the reaction!
active_component = component_ctx
tracking = true // Enable dependency tracking
active_dependency = null
is_mutating_allowed = false // Prevent mutations
// Destroy old child blocks (none yet)
destroy_computed_children(double)
// Run computation: () => _$_.get(count) * 2
value = double.fn()
// Inside fn(): _$_.get(count)
// This registers count as a dependency of double!
// No custom getter
IF double.a.get IS NOT undefined: // false
value = trigger_track_get(double.a.get, value)
RETURN value // 0
END FUNCTION
Inside double.fn(): _$_.get(count)
FUNCTION get_tracked(count):
value = count.__v // 0
// Register dependency (tracking === true, active_reaction === double)
IF tracking: // true
register_dependency(count) // Registers to double, not branch_block!
RETURN value // 0
END FUNCTION
Dependency registered to double:
double.d = {
c: 0, // count's clock value
t: count,
n: null
}
After computation:
double = {
__v: 0, // Computed value
c: 1, // Clock incremented
d: {
c: 0,
t: count,
n: null
}
// ...
}
Back to get_derived(double):
// Register double as dependency of branch_block
branch_block.d = {
c: 1, // double's clock value
t: double,
n: null
}
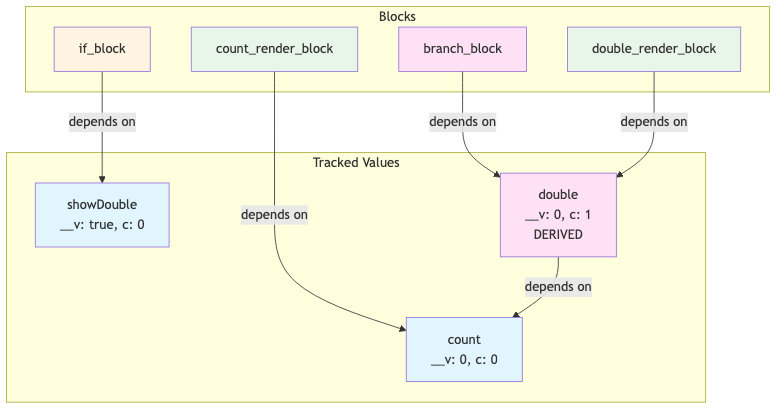
Final state after mount:
count = { __v: 0, c: 0, d: null, ... }
showDouble = { __v: true, c: 0, d: null, ... }
double = { __v: 0, c: 1, d: { c: 0, t: count, n: null }, ... }
count_render_block.d = { c: 0, t: count, n: null }
if_block.d = { c: 0, t: showDouble, n: null }
branch_block.d = { c: 1, t: double, n: null }
double.d = { c: 0, t: count, n: null }
Complete Dependency Graph After Mount:
Phase 3: User Interaction - Incrementing Count
Now that the component is mounted and all dependencies are registered, let's see what happens when the user clicks "Increment". This will change count from 0 to 1, triggering the update cycle that demonstrates how Ripple's reactivity system propagates changes.
Step 3.1: Event Handler Execution
User Action: Clicks button → @count++ executes
Compiled Code:
onClick: () => _$_.set(count, _$_.get(count) + 1)
Execution Flow:
Step 1: Read current value
_$_.get(count) // Returns 0
Context:
tracking = false // Not in tracking context (event handler)
active_reaction = null
Event handlers don't track dependencies because they're not reactive blocks. They simply read and write values without creating dependency relationships. This is important - event handlers are outside the reactive system, so they don't create dependencies when reading values.
Now let's see what happens when we actually update the value.
Step 2: Update value
_$_.set(count, 1) // Set count to 1
Algorithm: set(count, 1)
FUNCTION set(count, 1):
// Step 1: Check if mutations allowed
IF NOT is_mutating_allowed: // false (mutations allowed)
THROW Error('Assignments not allowed during computed evaluation')
// Step 2: Get old value
old_value = count.__v // 0
// Step 3: Early exit if value unchanged (optimization!)
IF 1 === 0: // false - value changed
RETURN
// Step 4: Get associated block
tracked_block = count.b // root_block (or component_ctx)
// Step 5: Store old value for teardown (if needed)
IF (tracked_block.f & CONTAINS_TEARDOWN) !== 0: // false
// Skip (no teardown needed)
// Step 6: Apply custom setter (none)
IF count.a.set IS NOT undefined: // false
value = untrack(() => count.a.set(1, 0))
// Step 7: Update value and clock (THE KEY!)
count.__v = 1 // Value updated
count.c = increment_clock() // Clock incremented!
// Step 8: Schedule update to associated block
schedule_update(count.b) // This triggers the update cycle!
END FUNCTION
Algorithm: increment_clock()
FUNCTION increment_clock():
clock = clock + 1 // Global clock: 0 → 1
RETURN clock // Returns 1
END FUNCTION
State Changes:
Before:
count = {
__v: 0, // Old value
c: 0, // Old clock
b: root_block,
// ...
}
clock = 0 // Global clock
After:
count = {
__v: 1, // Updated value
c: 1, // Clock incremented!
b: root_block,
// ...
}
clock = 1 // Global clock incremented
Key Point: The clock increment (count.c = 1) is crucial. This is how we detect changes later. When we check if a block is dirty, we compare count.c (current) with dependency.c (stored). Since 1 > 0, we know the value changed.
Clock-Based Change Detection:
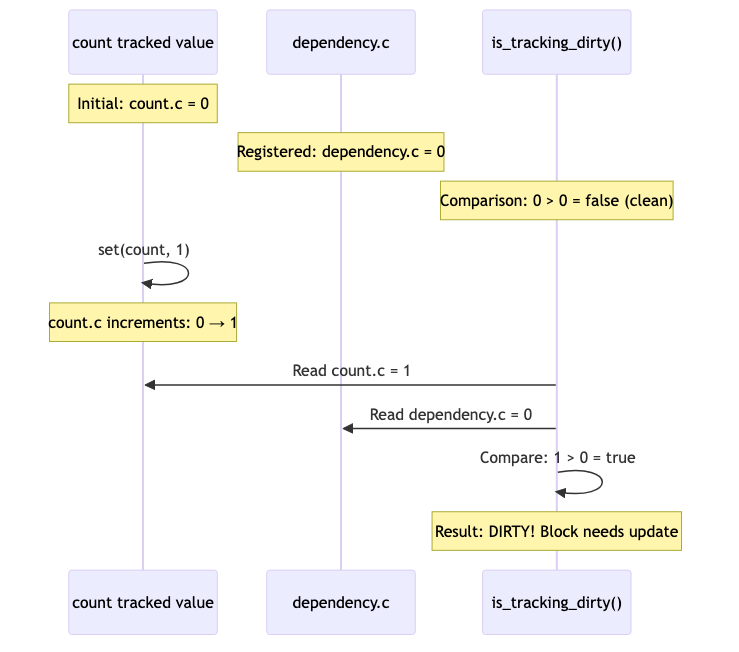
Now that the value is updated and the clock is incremented, we need to schedule an update to the blocks that depend on this value.
Step 3.2: Update Scheduling - Queuing the Update
Now that count has changed, we need to tell the system "hey, something changed, please update!" This is done through the scheduling system.
Code:
schedule_update(count.b) // count.b = root_block
Algorithm: schedule_update(root_block)
FUNCTION schedule_update(root_block):
// Step 1: Queue microtask (batches updates)
IF scheduler_mode === FLUSH_MICROTASK: // true
queue_microtask() // Schedules flush_microtasks()
// Step 2: Walk up block tree, marking blocks
current = root_block
WHILE current IS NOT NULL:
flags = current.f // ROOT_BLOCK
// Optimization: Already marked? Skip
IF (flags & CONTAINS_UPDATE) !== 0: // false
RETURN // Already scheduled
// Mark block as containing update
current.f = flags | CONTAINS_UPDATE
// Stop at root block (top of tree)
IF (flags & ROOT_BLOCK) !== 0: // true
BREAK
current = current.p // Would go to parent (none for root)
// Step 3: Add root block to update queue
queued_root_blocks.push(root_block)
END FUNCTION
State Changes:
Before:
root_block.f = ROOT_BLOCK
queued_root_blocks = []
is_micro_task_queued = false
After:
root_block.f = ROOT_BLOCK | CONTAINS_UPDATE // Marked for update
queued_root_blocks = [root_block] // Queued
is_micro_task_queued = true // Microtask scheduled
Algorithm: queue_microtask()
FUNCTION queue_microtask():
// Only queue once (batching optimization)
IF NOT is_micro_task_queued: // true
is_micro_task_queued = true
queueMicrotask(flush_microtasks) // ← Browser API: runs after current task
END FUNCTION
Why Microtask Batching?
Instead of updating immediately, Ripple batches updates using queueMicrotask(). This means multiple rapid changes result in a single update cycle, improving performance by reducing DOM updates. Updates happen after the current code finishes, providing predictable timing.
Example:
@count++ // Schedules update
@count++ // Already queued, no new microtask
@count++ // Already queued, no new microtask
// All three changes processed in single flush!
Now that the update is scheduled, let's see what happens when the microtask executes and flushes the updates.
Step 3.3: Microtask Flush
When the microtask executes:
Algorithm: flush_microtasks()
FUNCTION flush_microtasks():
is_micro_task_queued = false
// Execute queued microtasks (none)
IF queued_microtasks.length > 0: // false
// ...
// Safety check
IF flush_count > 1001: // false
RETURN
// Flush root blocks
previous_queued_root_blocks = queued_root_blocks // [root_block]
queued_root_blocks = []
flush_queued_root_blocks(previous_queued_root_blocks)
// Reset flush count
IF NOT is_micro_task_queued: // true
flush_count = 0
old_values.clear()
END FUNCTION
Algorithm: flush_queued_root_blocks([root_block])
FUNCTION flush_queued_root_blocks([root_block]):
FOR EACH root_block IN [root_block]:
flush_updates(root_block)
END FUNCTION
Step 3.4: Update Flush
Algorithm: flush_updates(root_block)
FUNCTION flush_updates(root_block):
current = root_block
containing_update = null
effects = []
// Depth-first traversal
WHILE current IS NOT NULL:
flags = current.f
// Track containing update block
IF (flags & CONTAINS_UPDATE) !== 0: // true for root_block
current.f = flags & ~CONTAINS_UPDATE // Clear flag
containing_update = root_block
// Execute block if not paused and inside update boundary
IF (flags & PAUSED) === 0 AND containing_update IS NOT NULL: // true
IF (flags & EFFECT_BLOCK) !== 0: // false
effects.push(current)
ELSE:
TRY:
// Check if dirty
IF is_block_dirty(current): // Check this!
run_block(current)
CATCH error:
handle_error(error, current)
// Traverse to first child
child = current.first // count_render_block
IF child IS NOT NULL:
current = child
CONTINUE
// Move to next sibling or parent
parent = current.p
current = current.next
// Walk up tree if no sibling
WHILE current IS NULL AND parent IS NOT NULL:
IF parent === containing_update:
containing_update = null
current = parent.next
parent = parent.p
// Execute effects
FOR EACH effect IN effects:
// ...
END FUNCTION
For root_block: is_block_dirty(root_block)
FUNCTION is_block_dirty(root_block):
flags = root_block.f
// Root blocks always execute
IF (flags & (ROOT_BLOCK | BRANCH_BLOCK)) !== 0: // true
RETURN false // Always dirty (always execute)
END FUNCTION
Root blocks and branch blocks always execute during flush_updates because they're structural elements that need to process their children. The is_block_dirty function returns false for these block types, but flush_updates still executes them because they serve as entry points for the traversal. The is_block_dirty check is primarily used for RENDER_BLOCK and EFFECT_BLOCK types to determine if they need re-execution.
For count_render_block: is_block_dirty(count_render_block)
FUNCTION is_block_dirty(count_render_block):
flags = count_render_block.f
// Not root or branch
IF (flags & (ROOT_BLOCK | BRANCH_BLOCK)) !== 0: // false
RETURN false
// Has run before
IF (flags & BLOCK_HAS_RUN) === 0: // false
block.f = flags | BLOCK_HAS_RUN
RETURN true
// Check dependencies
RETURN is_tracking_dirty(count_render_block.d)
END FUNCTION
Algorithm: is_tracking_dirty(count_render_block.d)
FUNCTION is_tracking_dirty(count_render_block.d):
dependency_chain = count_render_block.d // { c: 0, t: count, n: null }
IF dependency_chain IS NULL: // false
RETURN false
current = dependency_chain
WHILE current IS NOT NULL:
tracked = current.t // count
// Not derived
IF (tracked.f & DERIVED) !== 0: // false
update_derived(tracked)
// Check clock: count.c (1) > dependency.c (0)?
IF tracked.c > current.c: // 1 > 0 = true
RETURN true // DIRTY!
current = current.n // null
RETURN false
END FUNCTION
Result: is_block_dirty(count_render_block) returns true - block is dirty!
Execution: run_block(count_render_block)
FUNCTION run_block(count_render_block):
// Set context
active_block = count_render_block
active_reaction = count_render_block
tracking = true
active_dependency = null
// Execute: _$_.set_text(__text0.firstChild, 'Count: ' + _$_.get(count))
result = count_render_block.fn()
// Inside: _$_.get(count)
// Returns 1 (new value)
// Registers dependency again (updates clock in dependency node)
// Store dependency chain
count_render_block.d = active_dependency
END FUNCTION
Dependency updated:
count_render_block.d = {
c: 1, // Updated to current clock value
t: count,
n: null
}
DOM updated: Text node now shows "Count: 1"
Step 3.5: Derived Value Update - The Cascade
Now here's the beautiful part: double depends on count, so when count changes, double needs to recompute. But it only recomputes when someone actually reads it!
Derived Value Recomputation Flow:
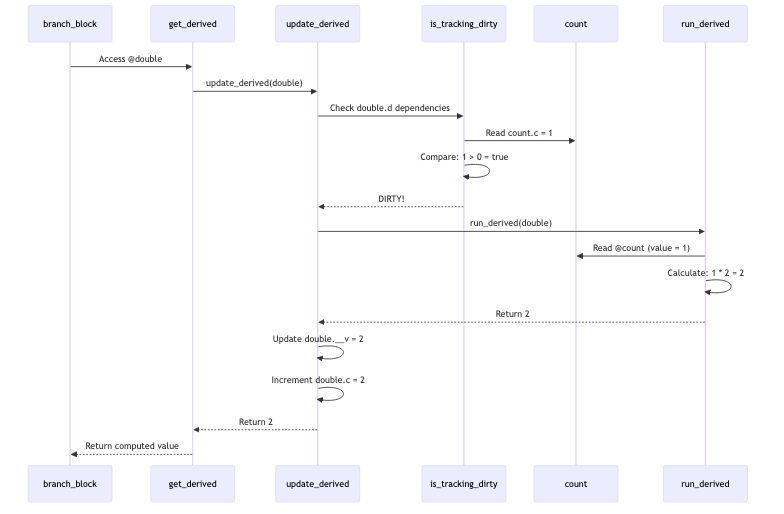
The Flow:
countchanged →count.c: 0 → 1count_render_blockupdated (we saw this)branch_blockexecutes (it always executes)- Inside branch:
_$_.get(double)is called - This triggers derived value computation!
For branch_block: is_block_dirty(branch_block)
FUNCTION is_block_dirty(branch_block):
flags = branch_block.f
// Branch blocks always execute (they're control flow)
IF (flags & BRANCH_BLOCK) !== 0: // true
RETURN false // Always execute (not "dirty" but always runs)
END FUNCTION
Why branch blocks always execute: Branch blocks (if, for) are control flow - they need to check conditions every time. They don't track dependencies themselves, but their children do.
Inside branch: _$_.get(double) - First Access!
This is where derived value computation happens:
FUNCTION get(double):
// double is derived
IF (double.f & DERIVED) !== 0: // true
RETURN get_derived(double) // ← Go here!
END FUNCTION
Algorithm: get_derived(double)
FUNCTION get_derived(double):
// Step 1: Update derived value (compute if needed)
update_derived(double)
// Step 2: Register dependency (branch_block depends on double)
IF tracking: // true
register_dependency(double)
// Step 3: Apply custom getter (none)
IF double.a.get IS NOT undefined: // false
double.__v = trigger_track_get(double.a.get, double.__v)
RETURN double.__v // 2
END FUNCTION
Algorithm: update_derived(double) - The Computation Check
FUNCTION update_derived(double):
value = double.__v // 0 (cached from before)
// Check if needs recomputation
IF value === UNINITIALIZED OR is_tracking_dirty(double.d): // Check!
// Dependencies changed, recompute!
value = run_derived(double)
// Update if value changed
IF value !== double.__v: // 2 !== 0 = true
double.__v = 2 // ← Update value
double.c = increment_clock() // ← Increment clock (2)
END FUNCTION
Algorithm: is_tracking_dirty(double.d) - Check if Count Changed
FUNCTION is_tracking_dirty(double.d):
dependency_chain = double.d // { c: 0, t: count, n: null }
current = dependency_chain
WHILE current IS NOT NULL:
tracked = current.t // count
// THE KEY COMPARISON!
// count.c (1) > dependency.c (0)?
IF tracked.c > current.c: // 1 > 0 = TRUE!
RETURN true // ← DIRTY! Dependencies changed!
current = current.n // null
RETURN false
END FUNCTION
Comparison:
| Value | Before | After |
|---|---|---|
count.c | 0 | 1 ← Changed! |
double.d.c (stored) | 0 | 0 |
| Comparison | - | 1 > 0 = true |
Result: Dependencies are dirty! Recompute double.
Algorithm: run_derived(double) - The Computation
FUNCTION run_derived(double):
// Save context
previous_block = active_block // branch_block
previous_reaction = active_reaction // branch_block
previous_tracking = tracking // true
previous_dependency = active_dependency // null
previous_is_mutating_allowed = is_mutating_allowed // true
TRY:
// Set context for computation
active_block = null // ← No block (computation context)
active_reaction = double // ← double is the reaction!
tracking = true // ← Enable dependency tracking
active_dependency = null // ← Will track count
is_mutating_allowed = false // ← Prevent mutations during computation
// Destroy old child blocks (none)
destroy_computed_children(double)
// Run computation: () => _$_.get(count) * 2
value = double.fn()
// Inside fn():
// _$_.get(count) → returns 1
// Registers count as dependency of double!
// 1 * 2 = 2
// No custom getter
IF double.a.get IS NOT undefined: // false
value = trigger_track_get(double.a.get, value)
RETURN value // 2
FINALLY:
// Restore context
active_block = previous_block
active_reaction = previous_reaction
tracking = previous_tracking
active_dependency = previous_dependency
is_mutating_allowed = previous_is_mutating_allowed
END FUNCTION
Context During Computation:
active_block = null // ← No block
active_reaction = double // ← double is the reaction!
tracking = true // ← Tracking enabled
active_dependency = null // ← Will be built
is_mutating_allowed = false // ← Mutations disabled
Inside double.fn(): _$_.get(count)
FUNCTION get_tracked(count):
value = count.__v // 1
// Register dependency (tracking === true, active_reaction === double)
IF tracking: // true
register_dependency(count) // Registers to double, not branch_block!
RETURN value // 1
END FUNCTION
Dependency Chain Updated:
Before:
double.d = {
c: 0, // ← Old clock value
t: count,
n: null
}
After:
double.d = {
c: 1, // Updated to count's current clock!
t: count,
n: null
}
Derived Value Updated:
Before:
double = {
__v: 0, // ← Old computed value
c: 1, // ← Old clock
d: { c: 0, t: count, n: null }
}
After:
double = {
__v: 2, // New computed value!
c: 2, // Clock incremented!
d: {
c: 1, // Updated dependency clock
t: count,
n: null
}
}
DOM Updated: Text node now shows "Double: 2"!
What Just Happened:
doubleaccessed →get_derived(double)called- Dependencies checked →
count.c (1) > double.d.c (0)= dirty! - Computation ran →
double.fn()executed, readcount(value1) - Dependency registered →
double.dupdated to trackcount - Value updated →
double.__v: 0 → 2,double.c: 1 → 2 - DOM updated → Text shows new value
Key Insight: Derived values are lazy and cached:
- They only compute when accessed
- They only recompute when dependencies are dirty
- They cache the result for subsequent accesses
Phase 4: Toggling ShowDouble
Now let's see what happens when the user clicks the "Toggle" button. This will change showDouble from true to false, demonstrating how conditional blocks respond to changes in their dependencies.
User clicks "Toggle" button: @showDouble = !@showDouble
Step 4.1: Value Update
_$_.set(showDouble, !_$_.get(showDouble))
Execution:
_$_.get(showDouble)returnstrue_$_.set(showDouble, false)executes
Algorithm: set(showDouble, false)
FUNCTION set(showDouble, false):
old_value = showDouble.__v // true
// Value changed
IF false === true: // false
RETURN
// Update value and clock
showDouble.__v = false
showDouble.c = increment_clock() // showDouble.c = 1
// Schedule update
schedule_update(showDouble.b) // root_block
END FUNCTION
Result:
showDouble = {
__v: false,
c: 1,
// ...
}
Step 4.2: Conditional Block Update
The if_block depends on showDouble, so it needs to re-execute.
For if_block: is_block_dirty(if_block)
FUNCTION is_block_dirty(if_block):
// Check dependencies
RETURN is_tracking_dirty(if_block.d)
END FUNCTION
FUNCTION is_tracking_dirty(if_block.d):
dependency_chain = if_block.d // { c: 0, t: showDouble, n: null }
current = dependency_chain
WHILE current IS NOT NULL:
tracked = current.t // showDouble
// Check clock: showDouble.c (1) > dependency.c (0)?
IF tracked.c > current.c: // 1 > 0 = true
RETURN true // DIRTY!
current = current.n
RETURN false
END FUNCTION
Result: if_block is dirty!
Execution: run_block(if_block)
FUNCTION run_block(if_block):
// Set context
active_block = if_block
active_reaction = if_block
tracking = true
active_dependency = null
// Execute: if (_$_.get(showDouble)) { ... }
result = if_block.fn()
// Inside: _$_.get(showDouble) returns false
// Registers dependency (updates clock)
// Condition is false, so set_branch is NOT called
// has_branch remains false
// After execution:
IF NOT has_branch: // true
update_branch(null, null) // Destroy branch!
END FUNCTION
Algorithm: update_branch(null, null)
FUNCTION update_branch(null, null):
condition = null
// Destroy old branch
IF b !== null: // true (branch_block exists)
destroy_block(branch_block)
b = null
END FUNCTION
Algorithm: destroy_block(branch_block)
FUNCTION destroy_block(branch_block):
// Destroy children recursively
destroy_block_children(branch_block)
// Run teardown
run_teardown(branch_block)
// Remove from DOM
remove_block_dom(branch_block.s.start, branch_block.s.end)
// Unlink from parent
// (parent.first/last/next pointers updated)
END FUNCTION
Result: The <p>Double: 2</p> element is removed from the DOM!
Dependency updated:
if_block.d = {
c: 1, // Updated to showDouble's current clock
t: showDouble,
n: null
}
Phase 5: Toggling Back
To complete our understanding, let's see what happens when the user clicks "Toggle" again. This demonstrates how the system handles conditional blocks that are recreated, and how derived values use caching to avoid unnecessary recomputation.
User clicks "Toggle" again: @showDouble = !@showDouble
Step 5.1: Value Update
showDouble.__v = true
showDouble.c = 2
Step 5.2: Conditional Block Re-execution
if_block is dirty (showDouble.c (2) > dependency.c (1))
Execution:
_$_.get(showDouble)returnstrue- Condition is
true, soset_branch()is called - New branch block is created
- Double value is rendered again
Inside branch: _$_.get(double)
FUNCTION get_derived(double):
update_derived(double)
// Check dependencies
is_tracking_dirty(double.d)
// count.c (1) > double.d.c (1)?
// 1 > 1 = false // NOT dirty!
// So use cached value
RETURN double.__v // 2 (cached!)
END FUNCTION
Key Point: The derived value is cached and doesn't recompute because count hasn't changed!
The Caching Check:
| Value | Current | Stored | Comparison |
|---|---|---|---|
count.c | 1 | 1 | 1 > 1 = false |
| Result | - | - | Not dirty → Use cache! |
This is the caching optimization in action - double was already computed when count was 1, so there's no need to recompute it again!
Performance Analysis
Now that we've traced through the complete lifecycle of our component, let's analyze the performance characteristics of Ripple's reactivity system. Understanding these metrics helps explain why the system is efficient and scales well.
Time Complexity
| Operation | Complexity | Notes |
|---|---|---|
get() (simple) | O(1) | Constant time read |
get() (derived) | O(C + D) | Computation + dependency check |
set() | O(H) | Height of block tree |
is_block_dirty() | O(D) | Dependency chain traversal |
flush_updates() | O(B) | All blocks in tree |
Where:
- C = computation time
- D = dependency count
- H = block tree height
- B = total blocks
Space Complexity
| Structure | Complexity | Notes |
|---|---|---|
| Tracked object | O(1) | Fixed size |
| Dependency chain | O(D) | One node per dependency |
| Block tree | O(B) | One block per reactive unit |
Optimizations Observed
- Dependency Deduplication: Same tracked value accessed multiple times creates only one dependency
- Clock-Based Change Detection: O(1) comparison vs O(N) equality check
- Lazy Derived Computation: Computed only when accessed and dirty
- Cached Derived Values: Don't recompute if dependencies unchanged
- Early Exit:
set()exits if value unchanged - Microtask Batching: Single DOM update cycle per event loop turn
Key Insights: The Big Picture
1. Fine-Grained Reactivity
Only the specific blocks that depend on changed values re-execute. In our example:
When count changes:
count_render_blockexecutes (depends oncount)doublecomputation runs (depends oncount)if_blockdoesn't execute (doesn't depend oncount)- Root block doesn't re-execute (not dirty)
When showDouble changes:
if_blockexecutes (depends onshowDouble)count_render_blockdoesn't execute (doesn't depend onshowDouble)doubledoesn't recompute (not accessed)
The Magic: Each block only re-executes when its specific dependencies change!
2. Dependency Chain Structure
Dependencies form a linked list on each block:
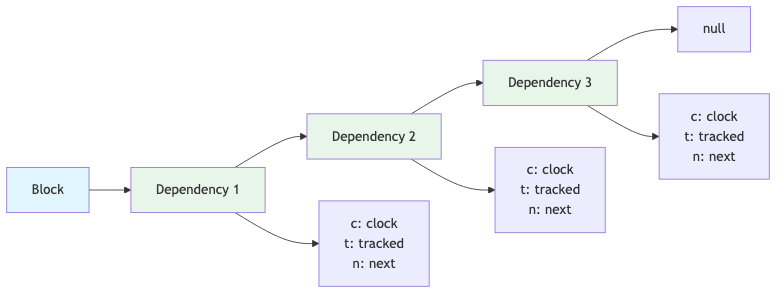
block.d → Dependency1 → Dependency2 → Dependency3 → null
↓ ↓ ↓
{c, t, n} {c, t, n} {c, t, n}
Each dependency node stores:
c: Clock value at registration time (for comparison)t: Reference to tracked value (which value it depends on)n: Next dependency (forms linked list)
Example from our component:
count_render_block.d → { c: 0, t: count, n: null }
This says: "This block depends on count, registered when count's clock was 0."
3. Clock-Based Change Detection
Instead of comparing values (expensive!), Ripple compares clock values:
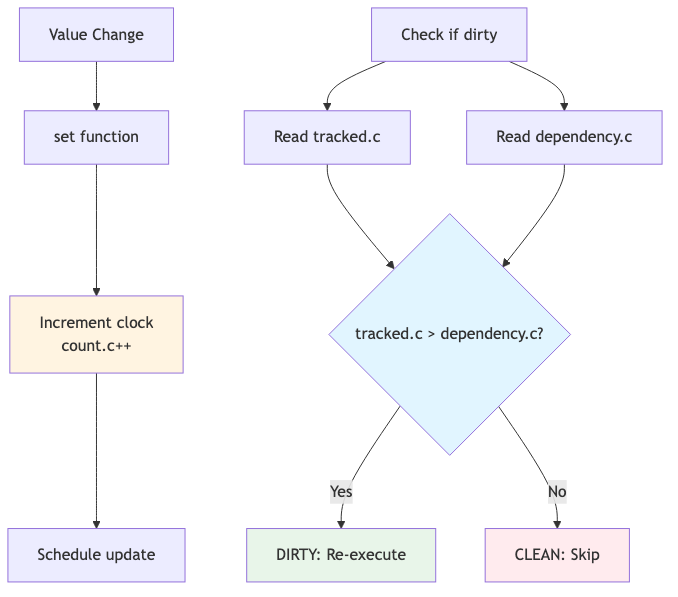
// Expensive (O(N) for objects):
if (tracked.__v !== dependency.stored_value) {
// Value changed!
}
// Efficient (O(1)):
if (tracked.c > dependency.c) {
// Value changed! (clock incremented)
}
Why this works:
- Every
set()increments the clock - Dependencies store the clock value when registered
- Comparison is just integer comparison (O(1))
Example:
// Initial state
count.c = 0
dependency.c = 0 // Registered when clock was 0
// After change
count.c = 1 // ← Incremented by set()
dependency.c = 0 // ← Still 0
// Check: 1 > 0 = true → DIRTY!
4. Derived Value Caching
Derived values cache their result and only recompute when:
Conditions for recomputation:
- First access:
__v === UNINITIALIZED - Dependencies dirty:
is_tracking_dirty(double.d) === true
Otherwise: Return cached value!
Example from our component:
// First access: count = 0
double.__v = 0 // Computed
// count changes to 1
count.c = 1
// Access double again
is_tracking_dirty(double.d) // 1 > 0 = true
double.__v = 2 // Recomputed
// Access double again (count still 1)
is_tracking_dirty(double.d) // 1 > 1 = false
double.__v = 2 // Cached! No recomputation!
This prevents unnecessary computation - if count hasn't changed, double doesn't recompute!
5. Block Tree Execution
Blocks form a tree structure:
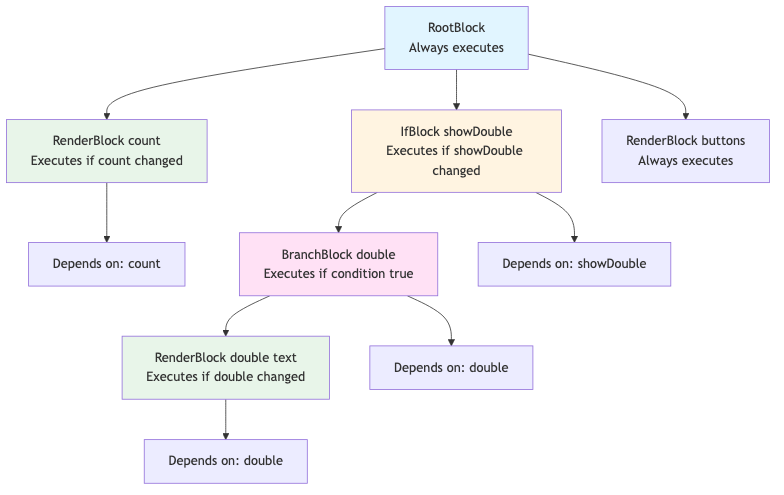
RootBlock (always executes)
├─→ RenderBlock (count) - executes if count changed
├─→ IfBlock (showDouble) - executes if showDouble changed
│ └─→ BranchBlock (double) - executes if condition true
│ └─→ RenderBlock (double text) - executes if double changed
└─→ RenderBlock (buttons) - always executes
Update Propagation:
- Updates start at root block
- Traverse down the tree (depth-first)
- Only dirty blocks execute
- Clean blocks skip execution
Visual Flow:
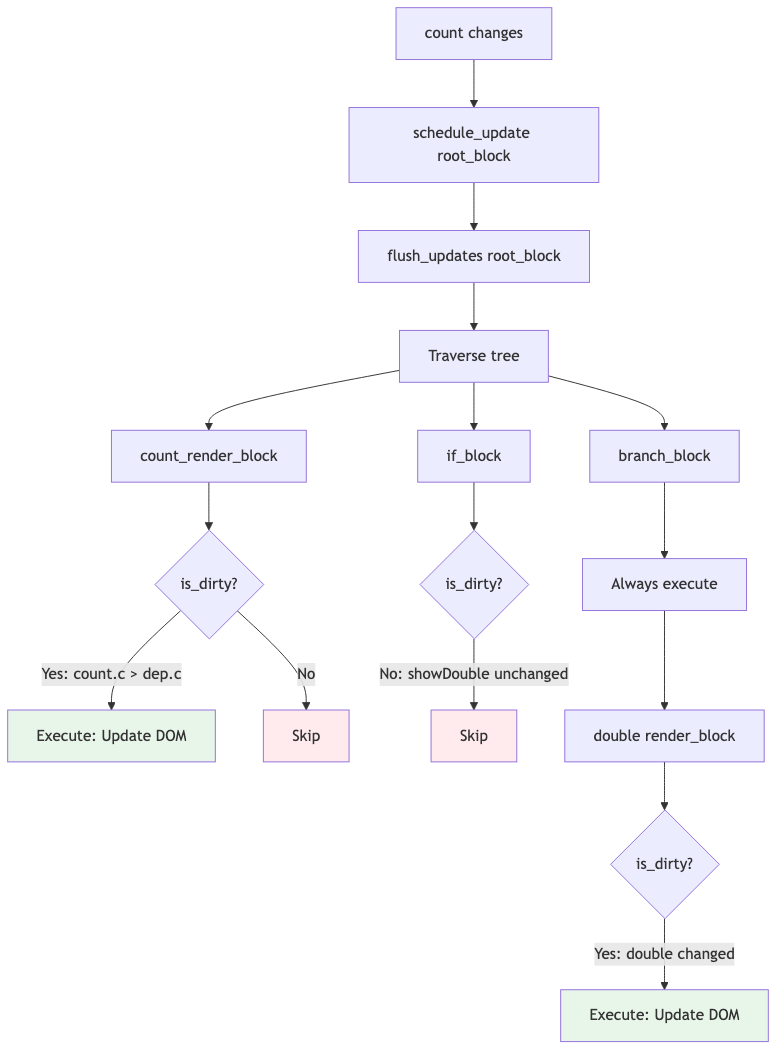
This is fine-grained reactivity - only what needs to update, updates!
Now that we've explored the key insights, let's summarize everything we've learned by tracing our component through its entire lifecycle:
Summary: The Complete Picture
Let's recap what we've learned by tracing our component through its entire lifecycle:
The Journey: From Code to DOM
1. Compilation: @count → _$_.get(count) (dependency tracking call)
2. Mount: Tracked values created, blocks execute, dependencies registered
3. User Action: @count++ → count.c increments (0 → 1)
4. Update Cycle: Microtask flushes, dirty blocks re-execute
5. Cascade: Derived values recompute when dependencies change
Key Data Structures We've Seen
Tracked Value:
{
__v: 0, // Current value
c: 0, // Clock (increments on change)
b: root_block, // Associated block (for scheduling)
f: TRACKED // Flags
}
Dependency Chain (Linked List):
{
c: 0, // Clock value when registered
t: count, // Reference to tracked value
n: null // Next dependency
}
Block:
{
d: dependency_chain, // Dependencies
f: RENDER_BLOCK, // Flags
fn: () => {...}, // Function to execute
p: parent_block, // Parent in tree
first: child_block // Children
}
The Core Algorithms
| Algorithm | Purpose | Key Insight |
|---|---|---|
get() | Read value | Registers dependency if tracking === true |
set() | Write value | Increments clock (c++), schedules update |
is_tracking_dirty() | Check changes | Compares tracked.c > dependency.c (O(1)!) |
schedule_update() | Queue update | Marks blocks, queues root block |
flush_updates() | Execute updates | Depth-first traversal, only dirty blocks run |
update_derived() | Compute derived | Lazy: only when accessed and dirty |
Performance Characteristics
Time Complexity:
get(): O(1) for simple, O(C+D) for derivedset(): O(H) where H = block tree heightis_block_dirty(): O(D) where D = dependency countflush_updates(): O(B) where B = blocks in tree
Optimizations:
- Clock-based change detection: O(1) comparison vs O(N) equality
- Dependency deduplication: Same value accessed twice = one dependency
- Node recycling: Reuse dependency nodes (memory optimization)
- Microtask batching: Single DOM update cycle per event loop
- Lazy derived computation: Compute only when needed
Conclusion
Ripple's reactivity system achieves fine-grained updates through a sophisticated combination of compile-time optimization and runtime efficiency:
The Magic Formula
Value Change → Clock Increment → Dependency Check → Block Re-execution → DOM Update
↓ ↓ ↓ ↓ ↓
@count++ count.c++ is_tracking_dirty() run_block() set_text()
Key Principles
- Compile-time wiring: The compiler transforms
@countinto_$_.get(count), setting up dependency tracking at build time - Runtime tracking: Dependencies are registered automatically during execution when
tracking === true - Efficient change detection: Clock-based comparison (
count.c > dependency.c) is O(1) vs expensive equality checks - Minimal re-execution: Only blocks with dirty dependencies re-execute (fine-grained!)
- Lazy computation: Derived values compute on-demand and cache results
Why This Matters
- Performance: Only affected blocks re-execute, not entire components
- Predictability: Clock-based change detection is deterministic
- Developer Experience: Automatic dependency tracking means less boilerplate
- Scalability: O(1) change detection scales to large applications
What We Learned
By tracing our example component, we saw:
- How
track()creates reactive values - How
@countbecomes a dependency registration - How clock values detect changes efficiently
- How the block tree executes updates
- How derived values compute lazily
- How microtask batching prevents thrashing
Next Steps
Understanding these internals helps you:
- Write efficient code: Know when blocks re-execute
- Debug issues: Understand dependency chains
- Optimize performance: Minimize unnecessary re-execution
- Appreciate the design: See the elegance in the system
The system's design choices—dependency deduplication, node recycling, microtask batching, lazy computation—all contribute to its excellent performance while maintaining developer ergonomics.
Try it yourself:
- Add
console.login render blocks to see when they execute - Create complex derived values and watch the lazy computation
- Profile your components to see the block tree structure
- Experiment with
untrack()to prevent dependency registration
Happy coding!
Quick Reference: Algorithms & Data Structures
Core Functions
track(value, get?, set?, block?)
- Creates tracked value or derived value
- Returns
TrackedorDerivedobject - Requires active component context
get(tracked)
- Reads tracked value
- Registers dependency if
tracking === true - Returns current value
set(tracked, value)
- Updates tracked value
- Increments clock (
tracked.c++) - Schedules update to associated block
- Early exit if
value === old_value
is_block_dirty(block)
- Checks if block needs re-execution
- Compares
tracked.c > dependency.cfor each dependency - Returns
trueif any dependency is dirty
schedule_update(block)
- Marks block tree with
CONTAINS_UPDATEflag - Queues root block for update
- Schedules microtask flush
flush_updates(root_block)
- Depth-first traversal of block tree
- Executes dirty blocks
- Skips clean blocks
Data Structure Fields
Tracked Object:
{
__v: any, // Current value
c: number, // Clock (increments on change)
b: Block, // Associated block
f: number, // Flags (TRACKED, DERIVED)
a: { // Accessors
get?: Function,
set?: Function
}
}
Derived Object (extends Tracked):
{
// ... all Tracked fields ...
fn: Function, // Computation function
d: Dependency, // Dependency chain
blocks: Block[], // Child blocks
co: Component // Component context
}
Dependency Node:
{
c: number, // Clock value when registered
t: Tracked, // Reference to tracked value
n: Dependency // Next dependency (linked list)
}
Block:
{
d: Dependency, // Dependency chain
f: number, // Flags (ROOT_BLOCK, RENDER_BLOCK, etc.)
fn: Function, // Function to execute
p: Block, // Parent block
first: Block, // First child
last: Block, // Last child
next: Block, // Next sibling
s: any, // State (DOM nodes, etc.)
t: Function, // Teardown function
co: Component // Component context
}
Global State Variables
active_block: Block | null // Current executing block
active_reaction: Block | Derived // Current reactive computation
active_component: Component | null // Current component
tracking: boolean // Enable dependency tracking
active_dependency: Dependency | null // Current dependency chain being built
clock: number // Global clock counter
queued_root_blocks: Block[] // Blocks queued for update
old_values: Map<Tracked, any> // Old values for teardown
Flag Constants
ROOT_BLOCK = 1 << 0 // Top-level component block
RENDER_BLOCK = 1 << 1 // DOM rendering block
BRANCH_BLOCK = 1 << 2 // Conditional/loop block
EFFECT_BLOCK = 1 << 3 // Side effect block
TRY_BLOCK = 1 << 4 // Error boundary block
TRACKED = 1 << 5 // Simple tracked value
DERIVED = 1 << 6 // Derived/computed value
BLOCK_HAS_RUN = 1 << 7 // Block has executed at least once
CONTAINS_UPDATE = 1 << 8 // Block contains updates
PAUSED = 1 << 9 // Block is paused
DESTROYED = 1 << 10 // Block is destroyed
Common Patterns
Reading a tracked value:
// Compiler transforms:
@count
// Into:
_$_.get(count)
// Which:
// 1. Returns count.__v
// 2. Registers dependency if tracking === true
// 3. Stores clock value in dependency.c
Writing a tracked value:
// Compiler transforms:
@count = 5
// Into:
_$_.set(count, 5)
// Which:
// 1. Updates count.__v = 5
// 2. Increments count.c++
// 3. Schedules update to count.b
Checking if value changed:
// Compare clocks:
if (tracked.c > dependency.c) {
// Value changed!
}
Further Reading
- Ripple Documentation - Official documentation